第一、幾種常用方法
讀取TXT文檔:urlopen()
讀取PDF文檔:pdfminer3k
第二、亂碼問題
(1)、
from urllib.request import urlopen
#訪問wiki內容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read())
輸出的結果中出現亂碼原因:
計算機只能處理0和1兩個數字,所以想要處理文本,必須把文本變成0和1這樣的數字,最早的計算機使用八個0和1表示一個字節,所以最大能夠表示整數是255=11111111.如果想要表示更大的數,必須使用更多的字節。
由于計算機是美國人發明的,所以最早只有127個字符被編寫進計算機,即常見的阿拉伯數字,字母大小寫,以及鍵盤上的符號。此編碼被稱為ASCII編碼,比如大寫字母A的ASCII編碼是65,65再被轉換二進制01000001,即是計算機處理的東西。
顯然,ASCII不能表示中文,故中國制定了自己的GB2312編碼,并且兼容ASCII編碼。問題是:使用GB2312編碼的慕課網三個字,假設編碼為61,62,63.但在ASCII碼表可能是其他字符。如下圖示,日文中的616263編碼成其他字符,打開后意思出錯。

解決方法:
國際上的unicode編碼,整合全世界所有編碼。故unicode編碼的內容在任一臺計算機用unicode仍正常打開
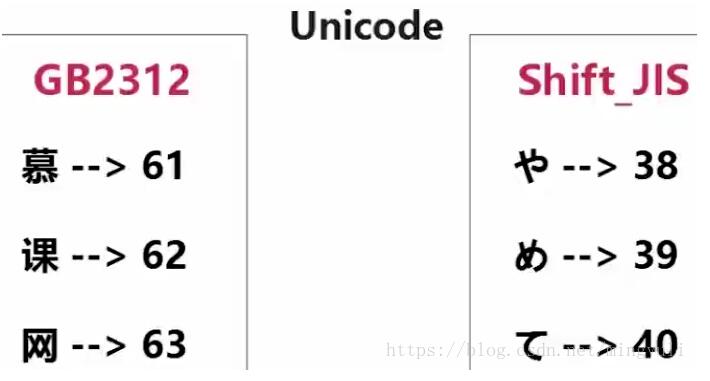
又對于A,ASCII編碼為01000001,Unicode編碼:0000000001000001此時浪費空間
故出現UTF-8編碼:01000001此時用兩個八位存儲中文。
(2)、記事本使用unicode編碼,將記事本存到計算機時,將轉化為utf-8儲存。
在計算機中打開文本時,將轉化為unicode編碼
存儲原因:使用utf-8儲存節省空間,使用unicode打開保證最大的兼容
(3)、服務器讀取uncode編碼的文檔,轉化為utf-8格式傳給瀏覽器。因為網絡帶寬昂貴,轉化為了減少負擔。
(4)、python3字符串默認使用Unicode編碼,所以python3支持多種語言
以Unicode表示的str通過encode()方法可以編碼為指定的bytes
如果bytes使用ASCII編碼,遇到ASCII碼表沒有的字符會以\x##表示,此時只用‘\x##'.decode('utf-8')即可
(5)、解決方法
from urllib.request import urlopen
#訪問wiki內容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read().decode("utf-8"))
第三、pdfminer3k安裝
法一:
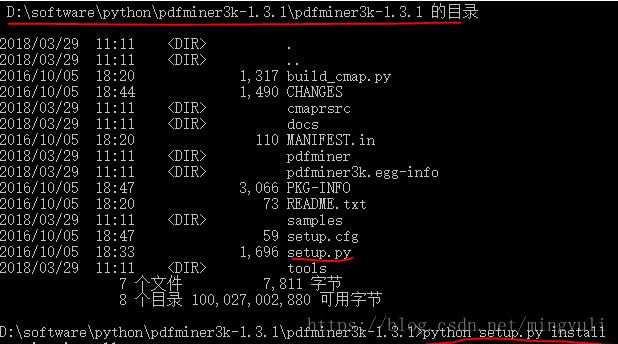
(1)、進入網址直接下載并解壓:https://pypi.python.org/pypi/pdfminer3k/
(2)、以管理員身份運行命令行窗口,進入軟件解壓縮位置,運行python setup.py install
法二:
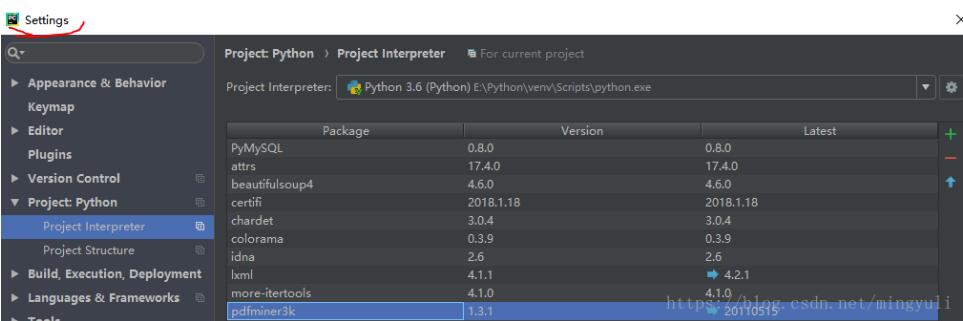
(3)、直接在pycharm中安裝
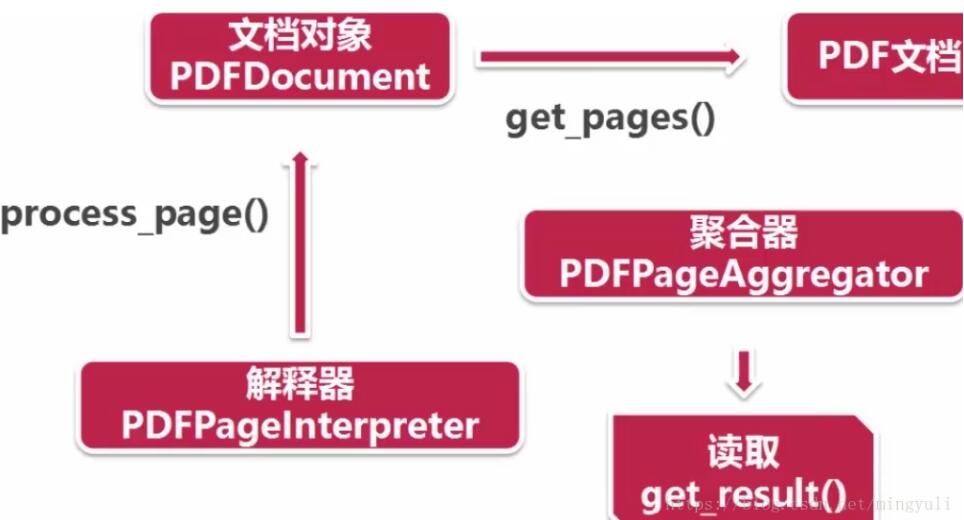
(4)、讀取pdf過程:首先創建一個分析器pdfparser和文檔對象pdfdocument,并通過兩個方法相互關聯,然后調用文檔對象的初始化方法(可以傳參數),此時資源內容被加載到文檔對象中。
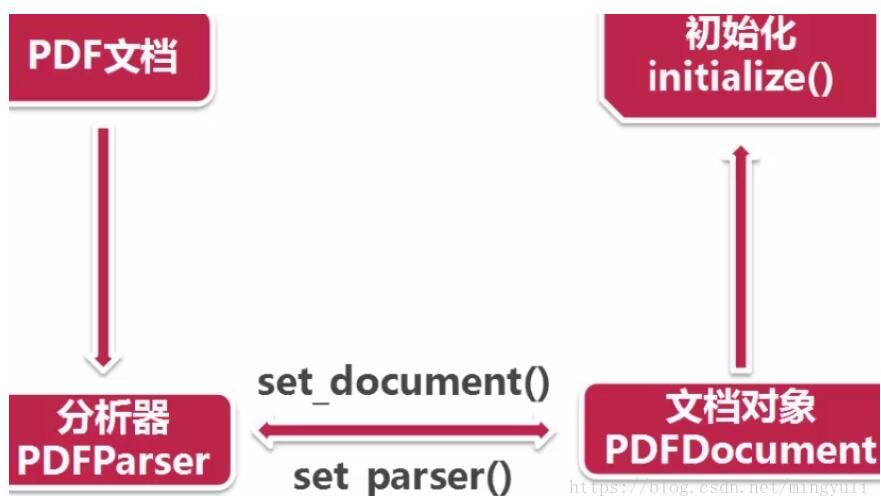
創建資源管理器和參數分析器,然后創建聚合器(整合資源管理器和參數分析器),通過聚合器創建解釋器(對pdf文檔進行編碼,解釋成python能識別的格式)
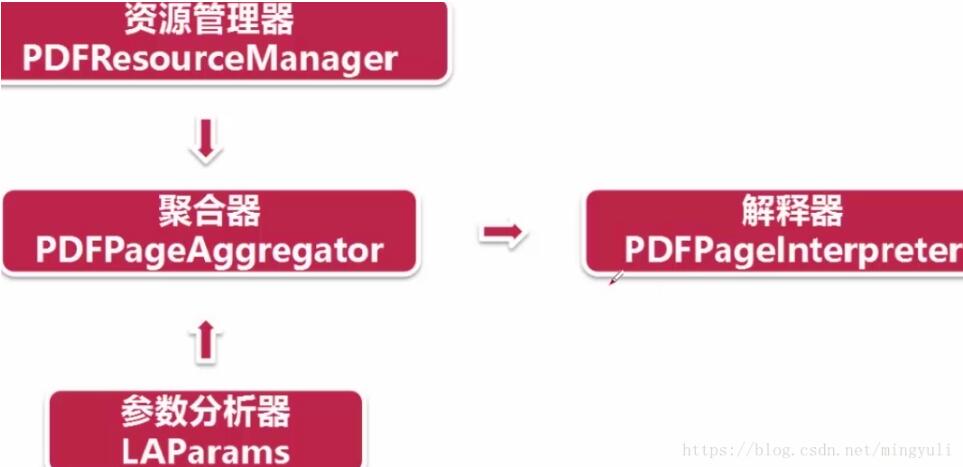
(5)、讀取pdf文檔:通過文檔對象的get_pages()方法得到pdf每一頁的內容,通過解釋器的process_page()方法讀取一頁一頁。
(6)、實例演示
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
#獲得文檔對象,以二進制讀方式打開
fp = open("naacl06-shinyama.pdf", "rb")
#創建一個與文檔關聯的分析器
parser = PDFParser(fp)
#創建一個pdf文檔的對象
doc = PDFDocument()
#連接解釋器與文檔對象
parser.set_document(doc)
doc.set_parser(parser)
#初始化文檔,如果文檔有密碼,寫與此。
doc.initialize("")
#創建pdf資源管理器
resource = PDFResourceManager()
#參數分析器
laparam = LAParams()
#創建聚合器
device = PDFPageAggregator(resource, laparams=laparam)
#創建pdf頁面解釋器
interpreter = PDFPageInterpreter(resource, device)
#使用文檔對象得到頁面的集合
for page in doc.get_pages():
#使用頁面解釋器讀取
interpreter.process_page(page)
#使用聚合器來獲得內容
layout = device.get_result()
for out in layout:
if hasattr(out, "get_text"):
print(out.get_text())
一下用于讀取網站上pdf內容
fp = urlopen(http://www.tencent.com/zh-cn/articles/8003251479983154.pdf)
補充內容:
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持腳本之家。如有錯誤或未考慮完全的地方,望不吝賜教。
您可能感興趣的文章:- Python爬蟲爬取全球疫情數據并存儲到mysql數據庫的步驟
- Python爬取騰訊疫情實時數據并存儲到mysql數據庫的示例代碼
- MySQL和Python交互的示例
- 配置python連接oracle讀取excel數據寫入數據庫的操作流程
- Python 對Excel求和、合并居中的操作
- 如何用python合并多個excel文件
- python基于pyppeteer制作PDF文件
- python操作mysql、excel、pdf的示例
